
私人健身房遇到偷拍怎麼辦?!

酒店偷拍约炮!

眼镜妹子深喉口交,开裆丝袜被干到好几次高潮。1

完全投入颅内高潮天堂1

UP主小桃采精挑战第三季,弄射幸运路人

TMW069用蜜穴教訓闢腿渣男

吞掉他连射好几次的精子-四次要命的高潮

混沌竞技场

我妹妹是最棒的點心 天野碧 高瀨里奈

麻豆传媒-下班后的搔痒难耐-夏禹熙

电梯小姐的骚逼服务1的!

双人高级内衣美女销售员诱惑连续射精的!

性感大屁股妹子做瑜伽被脱裤子后入套弄自己动大力猛操非常诱人1

绯色の刻 巻乃参!

18岁非常嫩的校花被约到酒店穿泳装为其口交

青梅竹馬三人五年不見的約會 直接順勢去酒店... 綾瀨心 川北明沙

MKMP-307 佐倉絆 初アナル解禁

DVDMS-490 一般男女ドキュメントAV 観光で来た中国人のデカ尻美熟女に僕の部屋を民泊利用で貸し出したその日から帰国する直前まで生ハメで何度も精子を搾り取られた(多謝)

下班回家来一发

麻豆传媒-花田性事-倪哇哇

【水果派】和S1七姐妹同居的后宫性生活1

年轻漂亮的美女和自称很厉害的中年网友酒店约啪说我要不许射啊!

愛人(梨穂)と温泉中出し不倫妻が出張で不在の二日間

被欲女女友榨干

苗条的正妹酒店硬搞

少女教育 雏田麻未编

麻豆传媒-突袭女优家EP9-欲火难耐逆推摄影师-袁子仪

C0930-hitozuma1417-FHD

JKとエロコンビニ店長小生意気蓮っ葉JK?栞~啜り画策ハメ千切り

一个长腿的女士欺负一个受虐狂的男人

91CM-188 童顔女秘堕落日记-渴求巨屌深插

1人分のザー

白丝少女的午休时间的!

176CM性感翘臀高跟大长腿美女和客人酒店啪啪,屁股超性感!

剑奴.1993

麻豆三十天特别企划 Day29—下一步—主观视角的情欲诱惑

纯天然大胸很少见,大屌爆操小骚逼,睡卧莲花1的!

対魔忍ユキカゼ #01 ユキカゼ编

りんかん倶楽部 ~第4话 真纪と素子

国产AV 糖心Vlog 花季富婆酒店玩弄按摩师!

MIDE-713 女体化M男を使ってあなたをオナニー誘導する淫語痴女 つぼみ

《精品推荐》高颜值极品女神后入骑乘淫叫呻吟不断

爆乳奴仆口爆吞精 性爱之始的!

【颜出】【无】【中出】以白衣天使为目标正在学习中的认真的?第一次拍照!黑上清秀大方系的苗条素人姑娘?

主动脱掉哥哥裤子口交吹箫打飞机,最后射在了嘴里每天都要吃肉棒

儿子搞上妈妈

罗哥选妃2020-06-18

【麻豆传媒】突袭女优家EP8 幸运粉丝参与真实性爱 苏语棠

4 満たされない人妻の禁断不倫SEX同じコンビニで働く男子大学生と汗だくで交わり続けた熱い夏… 橘京花

高颜值长相清秀妹子双人啪啪大秀多种姿势非常耐操床上干到阳台再到沙发身材苗条性欲很强

台北娜娜,丝袜诱惑足疗喷射1

多蜜汁的骚美女

91CM067 網貸1

DreamNote第一话

JDYP020 因約啪而開掛的人生1

JDSY003 縱欲小姑強上快遞員到高潮1

HDKA-191-CN はだかの家政婦 全裸家政婦紹介所 稲場るか

【水果派】自闭症患者の福音1

麻豆传媒-JK主播的迷奸餐强力春药拘束调教-张小九

酒店约操良家骚女,69姿势舔逼,大白屁股主动骑乘,打桩机猛操骚穴!

性奴经理

MGT-103 街角シロウトナンパ! vol.78美人妻をガチ口説き。4

JD110 又到櫻花綻放時1

【精品视频】娇嫩小白虎,清纯与淫荡的极度反差

上班时间抠B自慰摸到爽1

TM0092一起再看流星雨的!

乖巧的蝴蝶逼小少妇让小哥玩弄,逼逼里灌水洗干净才舔,嘴里叼着鸡巴让小哥抠穴,沙发上抱着草精彩又刺激

清纯校园风,JK学妹,170大长腿,甜美乖巧,娇喘呻吟勾魂

ニューハーフのペニクリを痴女が焦らし寸止めで虐め抜く! ちびとり#佐藤ののか

「誰かいやらしい目で私を見て…」野外露出でストレス発散する美人OLが通りすがりの覗き男に視姦され、ドM興奮。自ら羞恥調教を志願 塩見彩

网上认识很久的厂妹炮友准备回老家结婚前再约我一次!

新春快乐~打响第一炮!1

高颜值性感女神级美女酒店兼职援交!

91CM-128 弟妹跟我吧-楊柳1

处女们,任何污淫

定額料金でいつでもどこでもサブスク性交!!この学校では定額料金を支払えば女子生徒全員ところ構わず的!

彼女の妹が彼女の不在中に 舐めしゃぶりフェラごっくんしてくるので ボクは7年間も彼女と離れられない。的!

爱しのあの人に女の影! ずっと私と繋がって编

骚女激情4P,一男三女镜头前的淫荡,轮草三女激情抽插,淫声荡语不断

【水果派】被男友卖掉后被轮奸!1

男友眼睁睁看着她被强暴-夜班护士6

草莓巧克力香氛1

时隔30年重逢的同学和老师的!

台湾豪放美眉与外国男友的放荡生活

假如时间可以倒流,我愿意做你的性爱玩偶

SDJS-200 超敏感なスケベなマ○コにいきなり突撃! 巨根チ○ポで即ハメ!4本番 照れ屋ショートカット グッ

恋人是消防员2

满足宅男摄影师的一切要求

JKビッチに榨られたい1

CAPPV-081222_002-FHD

麻豆传媒-品尝邻居极品黑巨根

91CM-089 被報復的小姐-聶小倩1

三亚淫乱夜?前后夹击极品反差婊1

【柚子猫】《原神》复刻.五星女神刻晴对旅行者的性处理

(無修正) 幻夢館~愛欲と凌辱の淫罪~ 上巻

可可可渿子

上门卖延迟避孕套的学生,美女成了试验品,被操到腿抽筋

JK制服丝袜少女诱惑系列的!

纯欲系跟着我一起高潮1的!

想確認愛意 妻子和絕倫後輩二人獨處的三小時 不拔出的追擊中出16發 北條麻妃

没穿内内的人妻,刚干完就给老公电话汇报行踪

【网曝门事件】香港曾经地产经理马纪筠BelleMa性爱访谈+2017因FOXY软件性爱视频流出口交篇

「演艺圈事件」为上位被大佬潜规则的!

Reijoku-no-yakata-2-720p

肉感秘书室,秘书的射精业务报告的!

【水果派】《黑暗圣经》清纯少女遭爆菊,淫荡属性被激活!1

超高颜值情侣 酒店性爱自拍1

XK8116 誘奸兒媳-丹丹

雪梨小可爱,颜值女神躺在床上让小哥玩弄,吃奶抠逼小嘴就是最好的润滑剂,无套插入骚穴,精液全身嘴和脸上

大神直播小骚妇主播户外约了个猛男带回家啪啪下面毛多性欲强!

全程穿刺最后射在脸上1

ドSなマイナ会長サマがMノートに支配されました。~ドMに与する憧憬doS~

酒店援交的艺校妹子!

91KCM-023迷奸哥哥的漂亮人妻1

爱情魅惑的少女

捆绑调教饥渴母狗肉棒满足1

新世纪福音战士的新世纪性爱1

3D萝莉美少女的酷刑课

被插到淫水直流的巨乳模特的!

小肥猫咪

JL屌哥爆草高颜值95年小柠檬学生装泳装老师哥哥叫不停最后射嘴里

色情催眠师架按摩真爆射

91KCM-018調戲遠距上班中的姐姐1

爆操内射清纯乖乖女,第一段!

【C位女友系列】真实自拍女友的红韵真美

91CM-201 私人玩物的3p爆操,前后夹击口爆内射1

鬼父 下巻 「はしたない清楚なレギンス」 初回限定版!
![[夜桜字幕组][191102][华の妖精]はちゃめちゃ野球拳前编[GB]](https://lsbzytp.com:3519/upload/vod/20231010-1/ee5d4e0ac36122a98468fc713f349294.jpg)
[夜桜字幕组][191102][华の妖精]はちゃめちゃ野球拳前编[GB]

学园催眠隷奴 anime:01 あんたって本当に最低の屑だわ

淫行教師4 feat.エロ議員センセイ 静歌&初音~ガラス越

姐姐们放过我吧

爆乳粉红兔在线求精-许木学长的!

被限制在垃圾室并被迫身体服务的!

想確認愛意的妻子和絕倫後輩 二人獨處的三小時... 不拔出的追擊中出17發 黑川堇

爆乳美臀和男友激情性爱的!
![[milky] 艶母 taboo-1 「満たされぬ人妻」](https://lsbzytp.com:3519/upload/vod/20230910-1/8a0eaf02531b8bd42cce2d5cb17261cc.jpg)
[milky] 艶母 taboo-1 「満たされぬ人妻」

爱自慰的美少女30天禁止自慰!的!

东京街头搭讪两位美女进行4P
![[PORO] Floating Material 下巻 「こういうの……スキ_」](https://lsbzytp.com:3519/upload/vod/20231010-1/6d8772051a33ed6e3e3a335a8ab29358.jpg)
[PORO] Floating Material 下巻 「こういうの……スキ_」

NGR 因為義兄的侵犯第一次嚐到絕頂自慰的人妻 小松杏

爱圣天使ラブメアリー~悪性受胎~

Mother_Knows_Breast_01 Eng + Link in Comments

被恶心得要死的上司的大屌干得数度高潮的屈辱强奸的!

沉迷酒精 賭博 體力勞動者卻和模特級人妻每日做愛 人生大逆轉的我 星宮一花

太过亲近的变态家族的!

TM0141被欺凌的高中校花21

HEYDOUGA4030-2249 佐々木優奈-土下座懇願 M痴女

○交配 第一话 优等生の彼女はエルフのお姫様

91CM-156 反常的妻子-徐慧慧1

昔は細身で地味だったのに…再会したらムッチムチで性欲旺盛な幼馴染の豊満な肉体に僕の精子は限界まで搾り取られてしまった。 西村妮娜
![[メリー?ジェーン]女子高生の腰つき ビーチバレー部編 Round 2](https://lsbzytp.com:3519/upload/vod/20231010-1/4b890936272deefd5d0c5b2b66d2a47f.jpg)
[メリー?ジェーン]女子高生の腰つき ビーチバレー部編 Round 2

天使たちの素颜
JD080 JK萌妹愛家教

MIRANDA IN CHARGE MASS EFFECT FUTA MOVIE

股人タクシー 获物2 姉妹狩り?玲名と瀬名

饥渴美女发骚“老公求求你了,用你的大鸡巴使劲干死我吧,用你的大龟头使劲插”

无意识屁股受不了失控后背活塞运动

麻豆传媒-我的全部都属于你

ープでギャ

SQGY04 色情公寓EP4-夜夜1

绿帽子自拍流出

SM初体验 调教亚洲人妻小母狗皮鞭肛塞口交的!

6 運命の再会。少しの憐れみからすべてが変わってしまった。人妻なのに…情けない元上司のサオに堕とされた私。 美乃雀
![[MS-Pictures] 殻ノ少女 第1話](https://lsbzytp.com:3519/upload/vod/20230910-1/3459dcb4987847a05c14070e73be5ad2.jpg)
[MS-Pictures] 殻ノ少女 第1話

新婚的我在出差處和女上司共處一室 從早到晚被當成性奴 逆NTR 本真友里

1 2穴中出し集団痴漢バス5 女子校生限定SP的

3D Productions4

21时の女1!

漂亮的美女和炮友啪啪 很骚很主动裹屌舔舐爆射 没有几下就高潮

现役女高中生下海家庭教师指导性爱首次破处
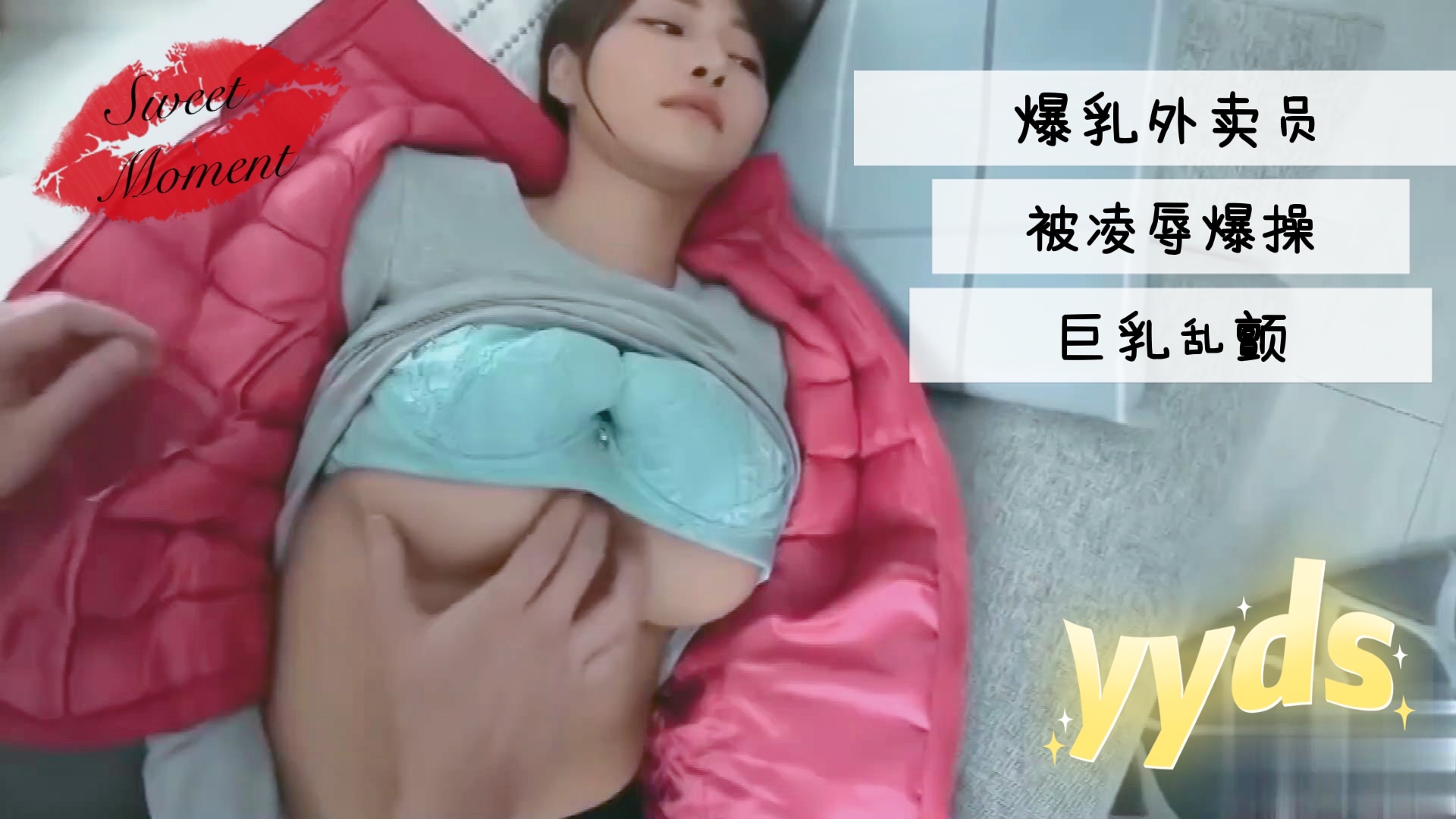
爆乳外卖员被凌辱爆操巨乳乱颤1

沈樵全集 10v 裸戏替身演员 沈樵 – 6.火车卧铺车厢铺邂逅前男友

巨乳千金在学园 第一话

今からアタシ……上巻初めてを捧げます

街头素人搭讪2 洛雪

边境县城小旅馆偷拍!!每嫖一个就拍一次!

心里骚看着清纯小姐姐

麻豆传媒-女子图鉴全新电影AV系列-徐蕾 凌薇

TMY0006 偷窺媽媽自慰

TM0112艷母2

摄影师外拍直接骑上性感模特1

【果冻传媒】91CM-020 名媛,拼多多假名媛被揭穿下场。
![人妻、蜜と肉 第三巻[月野定规]](https://lsbzytp.com:3519/upload/vod/20231010-1/77b5761abdb73b3c0415e46d8daf38dd.jpg)
人妻、蜜と肉 第三巻[月野定规]

去住宿的时候被这样的装束服侍而勃起的!

NGOD-115 日本ねとられ大賞受賞作品 嫁の尻に敷かれているタイプの僕が甘え上手な会社の後輩(童顔巨根)に男前な姉さん女房を寝盗られてしまった実話です… 美谷朱里

学园催眠隷奴 02 もうダメ、子宫に中出しされてイグゥ

高颜值苗条妹子和炮友浴室后入猛操非常诱人_很是诱惑

选美冠军彗星級性感新人,完美身材比例的大长腿「星宫一花」

下面有根棒棒糖-人家又被中出了1

白嫩少妇受不了秒射男老公,出来跟情人约会!

厦门饥渴少妇出轨性爱自拍,倒立口交,精液口爆

TMG06爆操騷貨親姐姐的!

超性感美女高清视频,大长腿,白屁股

【JVID】全空巨乳淫尻想要和你来场鱼水之欢的!

恋人是消防员6

全国探花 200810 1

鸭哥寻欢深夜网约极品高端外围

精神压力